flowchart BT
A["Shared definitions of terminologies for
LTC and supporting concepts"]
B["Shared cohort building code with
key subgroup stratification"]
C["Multivariate adjusted insights
and understanding of determinants"]
D["Predictive analytics pathways
with decision support and evaluation"]
A --> B --> C --> D
classDef gray fill:#fff, stroke:#333, stroke-width:1px
class A,B,C,D gray
Developing Use-Cases
The use-cases given here (Health Inequalities, Cardiovascular Risk Prediction, Cancer Pathway Mapping) are examples of analytics projects that can be supported within the SDE ecosystem, conducted in collaboration between ICB/NHS analytics teams and the AIC/SDE team. These population health align to the London Health Data Strategy and long term condition priorities, as well as national programmes such as CORE20PLUS5, and were proposed here following early discussions with London ICBs.
Building Reproducible Pipelines with ICBs
Within the new SDE infrastructure, Integrated Care Board (ICB) environments that are used for clinical or operational analytics and population health management, will share a common data model. Our teams are working with ICBs to build upwards from the basics of reproducible pipelines, required to support robust data science and predictive analytics (Figure 1). This means that any pipelines for cohort engineering or data science created in collaboration with one ICB, can be adapted and used for any other ICB (or deployed across multiple environments to create pan-London insights).
Sharing code, terminologies, and models
This approach reduces the need to centralise data for every project, and instead centralises and federates the common building blocks (Figure 2): (1) cohort definitions using the London-wide FHIR terminology server; (2) reproducible code for data engineering, analytics, and machine-learning, and (3) machine-learning model registration and storage.
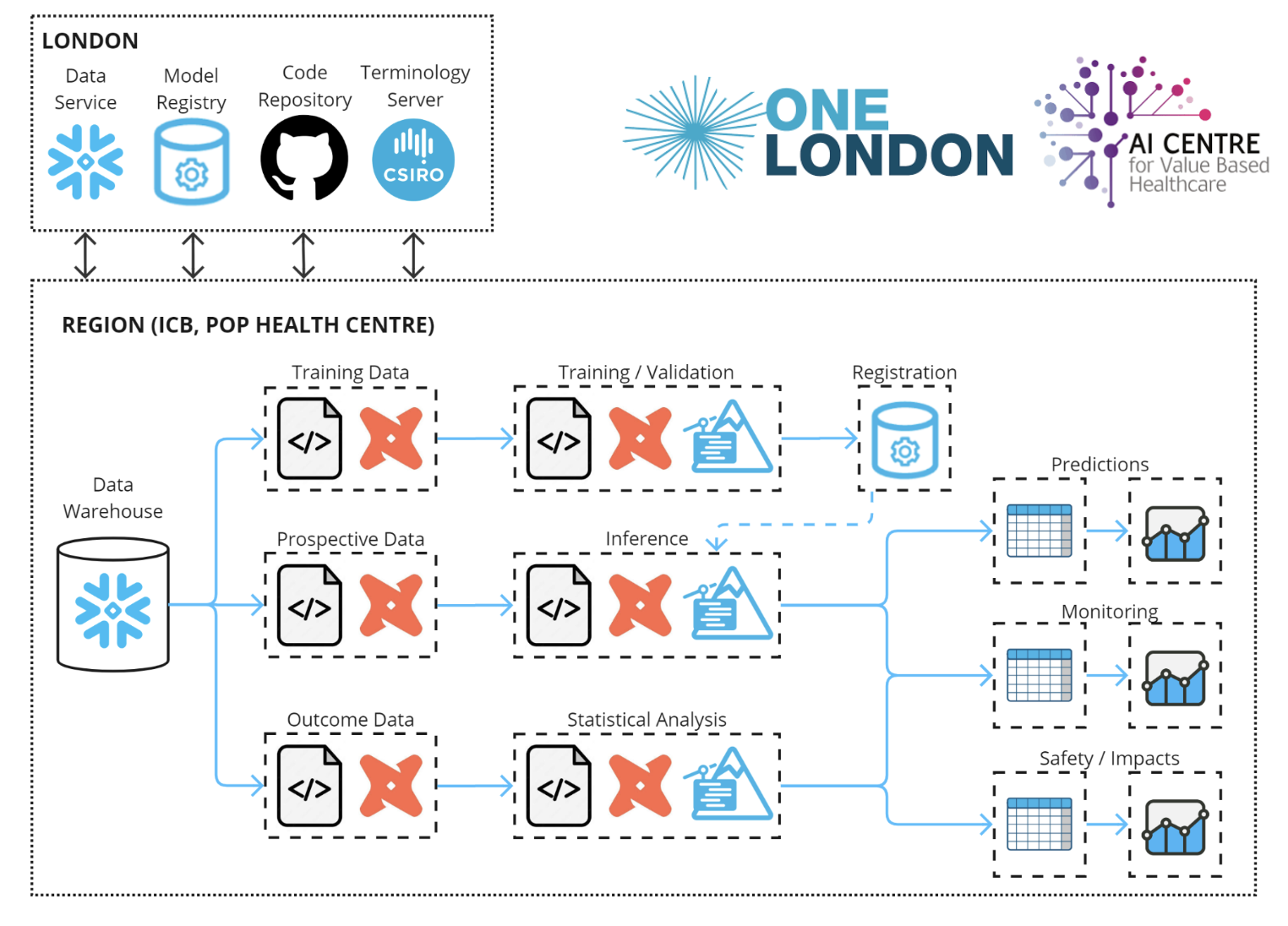
Sharing and iterating on these foundations improves analytical capabilities across the board - for example, a useful analytics dashboard developed in one ICB can be adapted another ICB to suit their local pathways with minimal work. Or, a predictive model trained in one ICB can be validated or receive additional training, and eventually deployed, in another ICB’s environment or on London-wide infrastructure.